When Migration Isn't Migration: Transforming Legacy Digital Humanities Sites
- Nick Steinwachs
- Jan 5
- 5 min read

Updated: Apr 3
Your digital humanities site is a decade old. It was cutting-edge when it launched, custom-built to showcase a unique collection with features no off-the-shelf platform could provide. Now the security warnings are piling up, the original developers are long gone, and staying on a supported version of Rails becomes its own project.
"Migration" is the wrong word for what you need. Migration assumes your data is portable. If your site predates broad IIIF adoption (roughly 2015-2016), it almost certainly isn't. There are no manifests to export, no standards-compliant data to move, just bespoke structures locked inside application code that hasn't been touched in years.
What you actually need is a transformation: reverse-engineering those custom structures and rebuilding them from scratch in modern, interoperable formats.
Three questions tell you which situation you're in:
Can you export IIIF manifests from your current system?
Does your site predate 2015?
Does it have features that standard platforms don't offer?
If you answered no, yes, and yes, you're looking at a transformation. Here's what that actually involves.
Mini Case Study: The Emily Dickinson Archive
Harvard's Emily Dickinson Archive demonstrates how close collaboration with scholarly stakeholders enables successful feature preservation in complex transformations.
The Emily Dickinson Archive (EDA) presented exactly the challenges this post describes: a decade-old bespoke Rails application, built before IIIF existed, with specialized scholarly features that no standard platform could replicate. Harvard's Library Technology Services needed to move this high-profile resource to sustainable infrastructure (their CURIOSity platform, a Spotlight implementation) without losing what made it valuable to Dickinson scholars worldwide.
The features that made this hard
Three capabilities defined the EDA's scholarly value, and none of them had obvious solutions in standard digital collection platforms:
A century of editorial transcriptions. Emily Dickinson's manuscripts are notoriously difficult to read—her handwriting is idiosyncratic, her punctuation unconventional, her line breaks ambiguous. Since the 1890s, multiple editors have produced transcriptions reflecting different scholarly interpretations. The Johnson edition (1955) made different choices than the Franklin edition (1998), which made different choices than scholars working from new manuscript discoveries.
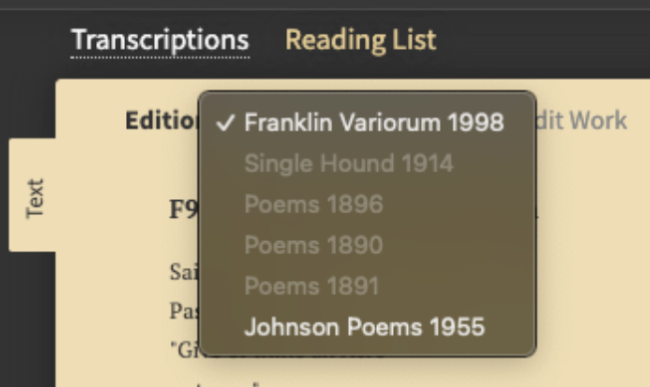
The original EDA displayed up to five transcription variants for a single poem. Scholars needed to compare them—not abstractly, but side-by-side with the manuscript image. Standard annotation models assume one authoritative transcription per image. The EDA needed many, each preserving its editorial provenance.
Physical versus metrical line breaks. Here's something non-specialists wouldn't know: the line breaks in Dickinson's manuscripts aren't the same as the line breaks in her poems. She wrote on small pieces of paper. When she ran out of room, she continued on the next line—a physical constraint, not a poetic choice. Editors later determined where the metrical line breaks should fall based on interpretation of rhythm and meaning.


Serious Dickinson scholarship requires toggling between these views: the poem as she physically wrote it versus the poem as editors interpret it. This isn't a standard viewer feature. It had to be reconstructed.
Formatted transcriptions with editorial apparatus. The transcriptions weren't plain text. They included strikethroughs where Dickinson crossed out words, insertions she added above the line, uncertain readings marked with editorial conventions. The original system stored this formatting in custom structures that had to be preserved through transformation and rendered correctly in the new viewer.

How dual-track agile made it work
We couldn't have preserved these features without continuous collaboration with the people who understood them. The project used dual-track agile methodology—running discovery and delivery in parallel, with scholars and curators directly involved throughout.
Weekly sprint planning with stakeholders.
Harvard's curatorial staff joined sprint planning sessions. They weren't just reviewing finished work—they were helping prioritize what mattered most. When we discovered that generating manifests with all transcriptions embedded created unwieldy 16MB files, they helped us understand which viewing patterns were essential and which were nice-to-have.
Continuous user testing.
Each sprint ended with demos to the scholarly stakeholders. The curator responsible for the collection tested actual research workflows against in-progress builds. This caught issues that technical review alone would miss—like ensuring the toggle between physical and metrical line breaks felt natural to someone doing real scholarship.
Bridging technical and curatorial vocabularies.
Previous conversations between technical and curatorial teams had created tension; they were discussing requirements in different vocabularies. We helped curators understand the technical constraints, and helped developers understand what scholars actually needed.
The Outcome
In four one-week sprints, we transformed approximately 4,800 works into IIIF Presentation API 3.0 compliant manifests.

We developed a custom Mirador plugin that displays multiple transcription variants with toggle controls for line break interpretation. We extended Harvard's Media Presentation Service to support the annotation patterns the EDA required—infrastructure that's now available for other Harvard collections with similar needs.
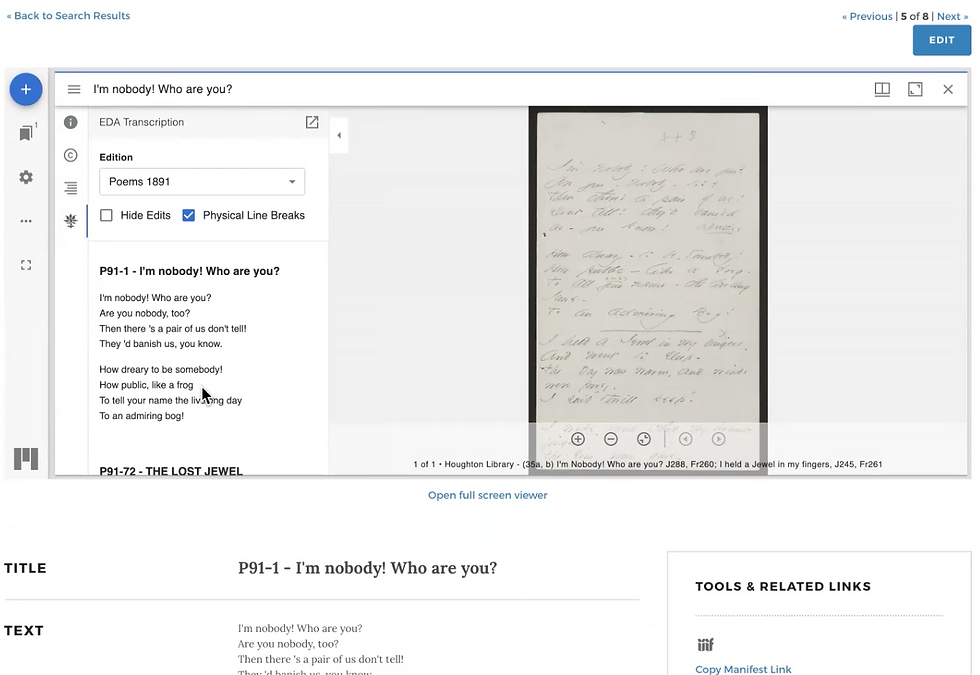
The specialized features Dickinson scholars depended on? Preserved. The security vulnerabilities that had flagged the original site for years? Eliminated. And because we built on IIIF standards and Spotlight infrastructure, the upgrade path is clear for years to come.
More importantly: the patterns we developed—for handling multiple annotation layers, for preserving formatted transcriptions, for extending standard viewers with custom plugins—are reusable. The next institution facing a similar transformation doesn't have to start from scratch.
FAQ
How much does a transformation project cost? Costs vary significantly based on collection size, feature complexity, and institutional requirements. A focused transformation of a moderately complex DH site typically requires 4-8 weeks of development effort. We recommend a scoping engagement to assess your specific situation before committing to estimates.
Can you do this work in-house? Possibly, if your team has experience with IIIF, the target platform (Spotlight, Blacklight, etc.), and complex data transformation. The challenge is usually the reverse-engineering of legacy systems—it requires both technical skill and experience recognizing patterns in undocumented code.
What happens to our existing URLs? URL preservation and redirect strategies are part of transformation planning. Scholarly citations to your current site shouldn't break. This requires coordination between the transformation work and your infrastructure team.
Do we have to use Spotlight or Blacklight? No—IIIF-compliant content can work with any standards-based platform. However, Spotlight and Blacklight are well-suited for curated digital collections and have active open-source communities. We recommend them for most academic use cases.
How do we maintain the transformed site long-term? Because the new platform uses standard technologies and community-supported software, ongoing maintenance is straightforward. Your library IT team can handle routine updates. Feature enhancements can be contributed back to open-source communities, further reducing long-term maintenance burden.
